| Разработчики: | Колумбийская школа инженерных и прикладных наук |
| Дата премьеры системы: | апрель 2022 г |
| Отрасли: | Информационные технологии |
| Технологии: | Речевые технологии |
Содержание |
История
2022: Анонс системы
В середине апреля 2022 года ученые Колумбийского инженерного института разработали систему, генерирующую тихие звуки, которые можно включить в любой комнате для того, чтобы заблокировать умные устройства от слежки за пользователями. Технологию легко внедрить в аппаратные средства, такие как компьютеры и смартфоны, предоставляя людям возможность самостоятельно защищать конфиденциальность своего голоса.
Несмотря на то, что теоретически результаты, полученные командой в области искажения систем автоматического распознавания речи, уже были известны, их достижения достаточно быстро для использования в практических приложениях оставалось основным узким местом. Проблема заключалась в том, что звук, который прерывает речь человека до апреля 2022 года, не являлся звуком, который прервет речь секундой позже. Когда пользователи говорят, их голоса постоянно меняются, поскольку они произносят разные слова с различной скоростью и тональностью. Эти изменения делают практически невозможным для машины поспевать за быстрым темпом речи человека.

| | Ключевой технической задачей для достижения этой цели было заставить все это работать достаточно быстро! Наш алгоритм, которому удается блокировать неавторизованный микрофон от правильного восприятия ваших слов в 80% случаев, является самым быстрым и самым точным на нашей тестовой площадке. Он работает даже тогда, когда мы ничего не знаем о неавторизованном микрофоне, например, о его местонахождении или даже о компьютерном программном обеспечении, работающем на нем. По сути, алгоритм маскирует голос человека в эфире, скрывая его от этих прослушивающих систем и не мешая разговору между людьми в комнате, - сказал доцент кафедры информатики Карл Вондрик (Carl Vondrick). | |
Исследователям необходимо было разработать алгоритм, который мог бы разрушать нейронные сети в реальном времени, который мог бы генерироваться непрерывно по мере произнесения речи и был бы применим к большинству словарных слов в языке. Хотя предыдущие работы успешно справлялись хотя бы с одним из этих трех требований, ни одна из них не достигла всех трех. Ведущий автор исследования и аспирант в лаборатории Миа Вондрика рассказала, что алгоритм использует то, что она называет предиктивными атаками – это сигнал, который может нарушить любое слово, транскрибировать которое обучены модели автоматического распознавания речи. Кроме того, когда звуки атаки воспроизводятся в эфире, они должны быть достаточно громкими, чтобы нарушить работу любого несанкционированного микрофона, который может находиться на большом расстоянии. Звук атаки должен передаваться на то же расстояние, что и голос.Российский рынок СЭД/ECM борется с демпингом и рассчитывает на возможности искусственного интеллекта. Обзор и рейтинг TAdviser 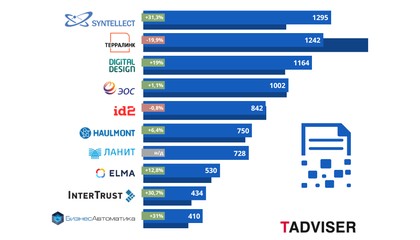
Подход исследователей достигает производительности в реальном времени, прогнозируя атаку на будущий сигнал или слово на основе двух секунд входной речи. Группа оптимизировала атаку таким образом, чтобы она имела громкость, схожую с обычным фоновым шумом, что позволяет людям в комнате вести беседу естественно и без успешного мониторинга автоматической системой распознавания речи. Группа успешно продемонстрировала, что их метод работает в реальных помещениях с естественным окружающим шумом и сложной геометрией сцены.[1]



